
We present DepthFM, a versatile and fast state-of-the-art generative monocular depth estimation model. Beyond conventional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within few inference steps.
The gallery below presents images sourced from the internet, accompanied by a comparison between our DepthFM, ZoeDepth, and Marigold. Utilize the slider and gestures to reveal details on both sides. Note that our depth maps in the first two rows are generated with 10 inference steps, while the last row showcases our results with one single inference step compared to Marigold with two inference steps. We achieve significantly faster inference speed with minimal performance sacrifices.























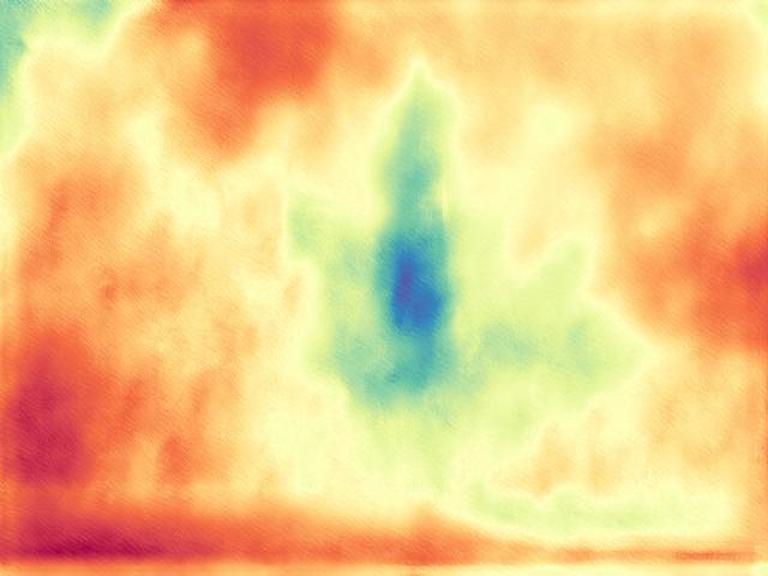








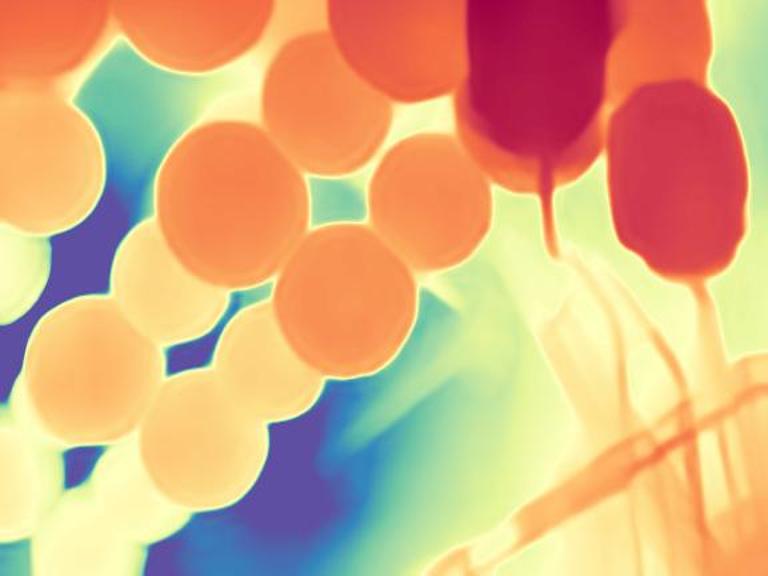
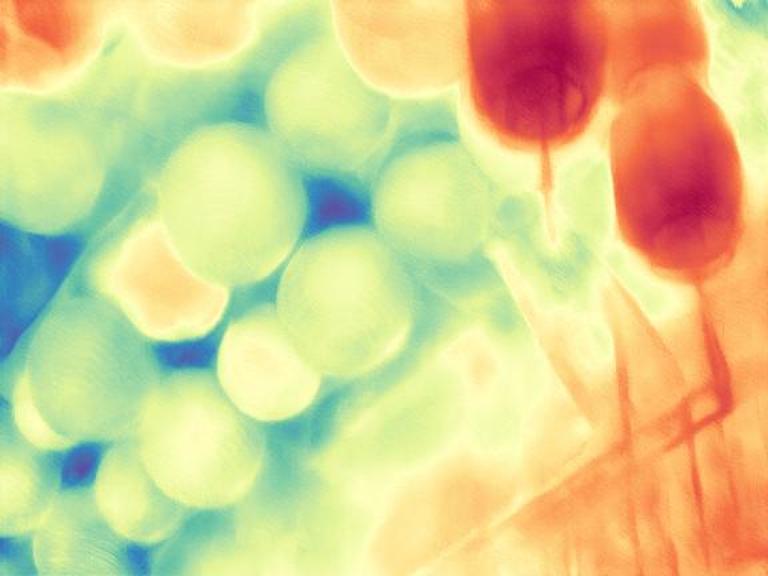















































































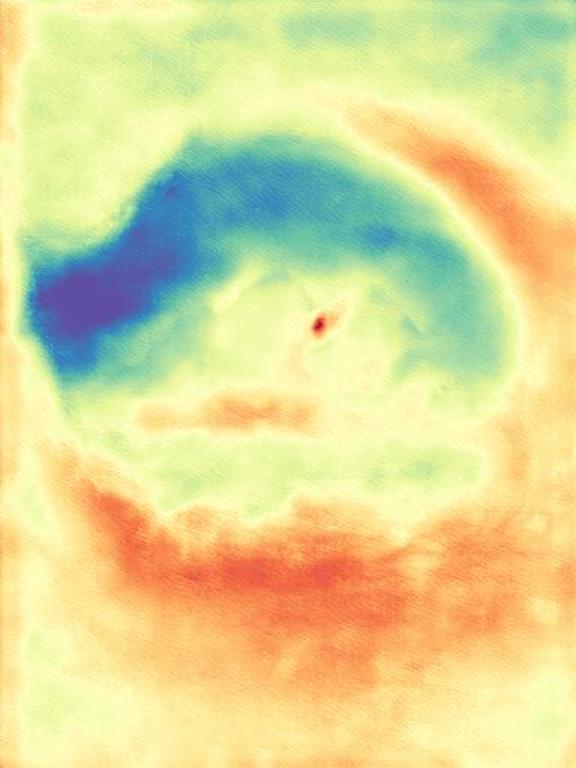

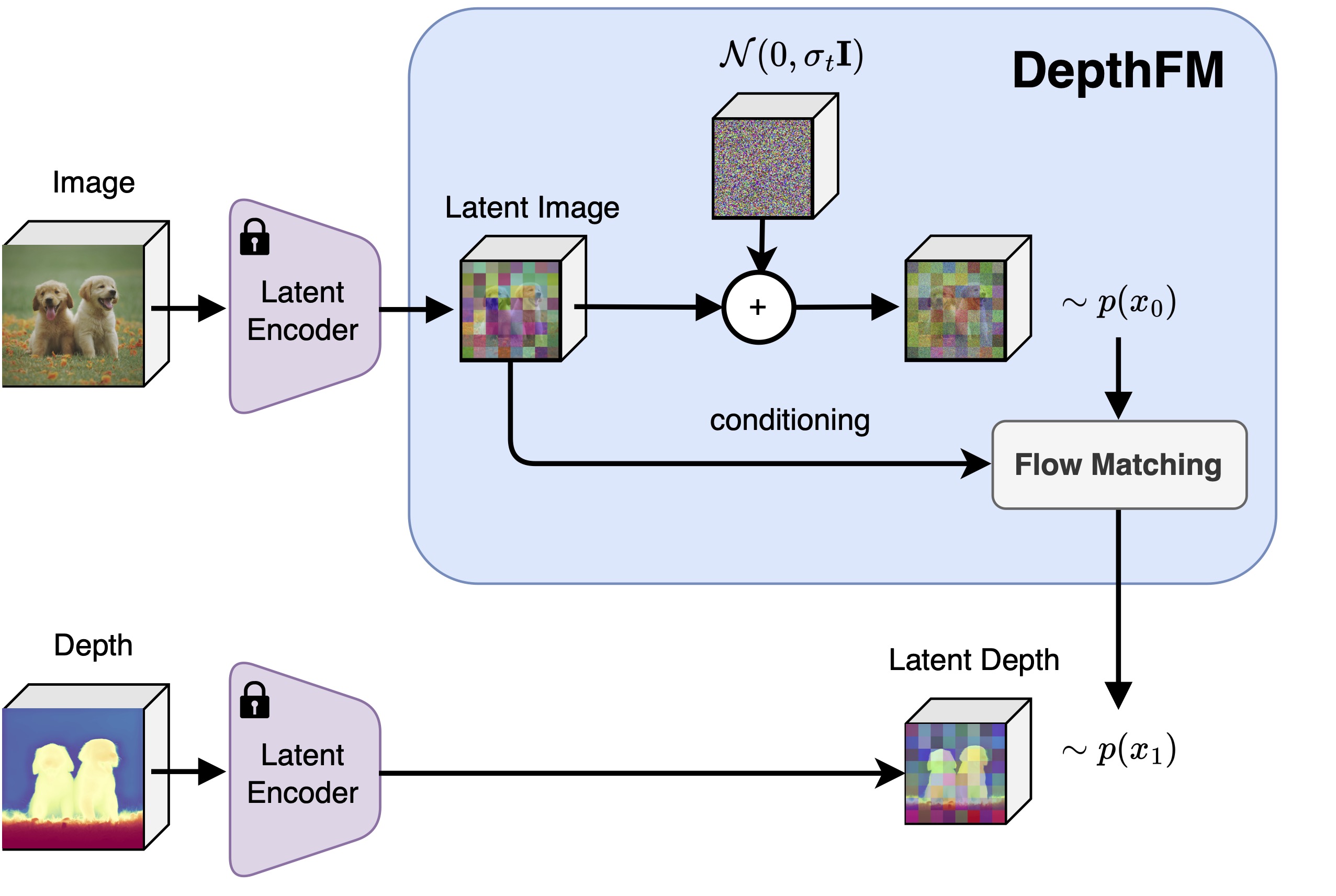
DepthFM regresses a straight vector field between image distribution $x$ and depth distribution $d$ by leveraging the image-to-depth pairs. This approach facilitates efficient few-step inference without sacrificing performance.
We demonstrate the successful transfer of the strong image prior from a foundation image synthesis diffusion model (Stable Diffusion v2-1) to a flow matching model with minimal reliance on training data and without the need for real-world images.
To further boost our model performance and robustness, we employ synthetic data and utilize image-depth pairs generated by a discriminative model on an in-the-wild image dataset.
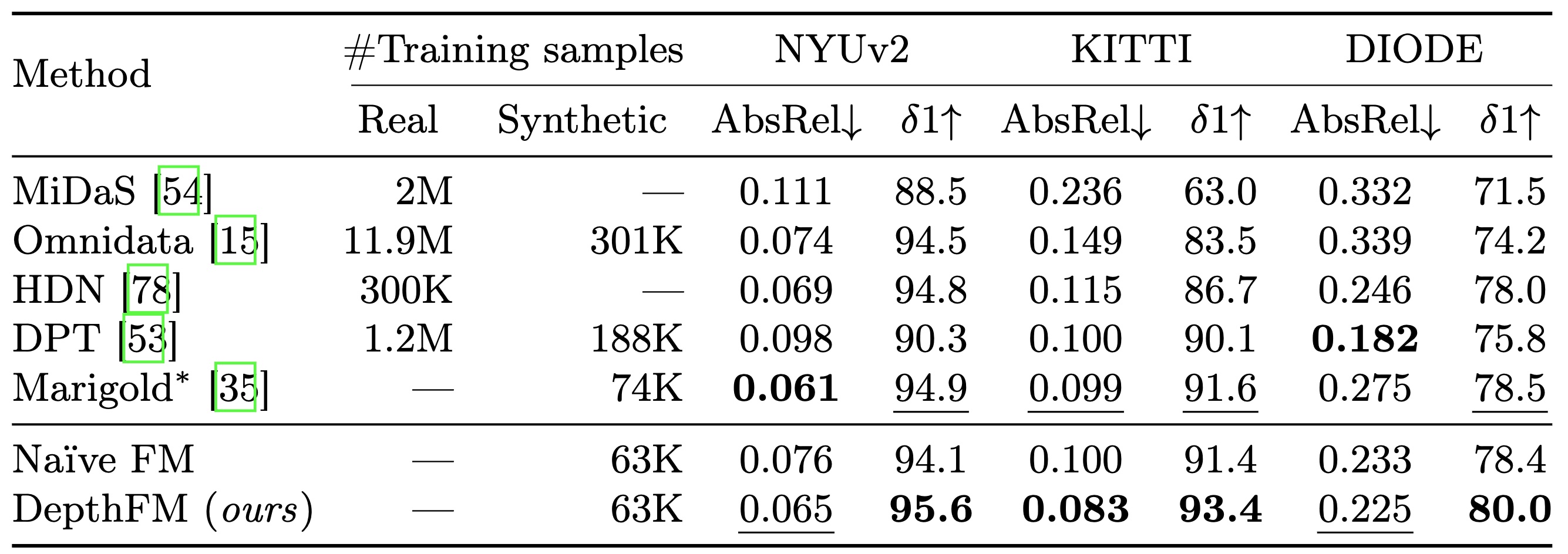
Quantitative comparison of DepthFM with affine-invariant depth estimators on several zero-shot benchmarks. Bold numbers are the best, underscored second best. Our method outperforms other methods on both indoor and outdoor scenes in most cases with only little training on purely synthetic datasets.
Refer to the pdf paper linked above for more details on qualitative, quantitative, and ablation studies.
@misc{gui2024depthfm,
title={DepthFM: Fast Monocular Depth Estimation with Flow Matching},
author={Ming Gui and Johannes Schusterbauer and Ulrich Prestel and Pingchuan Ma and Dmytro Kotovenko and Olga Grebenkova and Stefan Andreas Baumann and Vincent Tao Hu and Björn Ommer},
year={2024},
eprint={2403.13788},
archivePrefix={arXiv},
primaryClass={cs.CV}
}